Indicator functions are designed to work based on data stored as a list - which is the default structure for a complex hierarchical survey dataset with nested tables.
The default export format from kobotoolbox includes variables names generated as a concatenation of groups and names.
The indicators calculation are based on specific patterns to be identified within the variable names. This allow to handle cases where variables and questions would have been shifted within the sequence of the questionnaire and through different questions groups.
The indicator functions also check that the data content is the one expected.
A check log is displayed in the console to keep track of all issues
Generating data from a specific form definition
One key function is to generate a dummy dataset based on a specific form structure To demonstrate the package we will use the standard questionnaire and then apply each indicator function to demonstrate them.
We can then also re-use the function to create dummy data based on any form and then apply each indicator function to actually verify which indicators can be created based on the form content.
fct_var_dummy
## let's initiate a dataframe with an index of n r records
n <- 384
frame <- dplyr::tibble(
index = paste0( "ID-",
purrr::as_vector(
purrr::map(n, sample(LETTERS, 4)) |>
purrr::map(paste0, collapse = "")),
"-",
formatC(1:n, width = nchar(n) + 1, flag = "0")
))
## test inject select_one
frame <- fct_var_dummy(
frame = frame,
name = "testselect_one",
type = "select_one",
list_opt = c("alpha", "beta", "delta"),
constraint = NULL
)
## test inject select_multiple in main
frame <- fct_var_dummy(
frame = frame,
name = "testselect_multiple",
type = "select_multiple",
list_opt = c("alpha", "beta", "delta"),
constraint = NULL
)
## test inject text
frame <- fct_var_dummy(
frame = frame,
name = "testtext",
type = "text",
list_opt = NULL,
constraint = NULL
)
## test inject numeric
frame <- fct_var_dummy(
frame = frame,
name = "testnumeric",
type = "numeric",
list_opt = NULL,
constraint = NULL
)
## test inject date
frame <- fct_var_dummy(
frame = frame,
name = "testdate",
type = "date",
list_opt = NULL,
constraint = NULL
)
## Preview out out
knitr::kable(head(frame, 5))| index | testselect_one | testselect_multiple_alpha | testselect_multiple_beta | testselect_multiple_delta | testtext | testnumeric | testdate |
|---|---|---|---|---|---|---|---|
| ID–0001 | beta | 1 | 1 | 1 | FreeText_-0001 | 60 | 2020-05-20 16:30:59 |
| ID–0002 | alpha | 1 | 0 | 1 | FreeText_-0002 | 5 | 2021-11-09 06:47:05 |
| ID–0003 | beta | 1 | 0 | 0 | FreeText_-0003 | 75 | 2021-02-17 17:35:59 |
| ID–0004 | beta | 1 | 1 | 1 | FreeText_-0004 | 39 | 2021-06-14 10:43:58 |
| ID–0005 | alpha | 1 | 0 | 0 | FreeText_-0005 | 7 | 2022-09-27 23:57:16 |
fct_kobo_dummy
## generate dummy dataset for different form version
## CAPI
form <- system.file("RMS_CAPI_v2.xlsx", package = "IndicatorCalc")
datalist <- fct_kobo_dummy(form,
n = 384,
file = NULL)
# openxlsx::write.xlsx(datalist, here::here("inst", "dummy_RMS_CAPI_v2.xlsx"))
form <- system.file("RMS_CAPI_v3.xlsx", package = "IndicatorCalc")
datalist <- fct_kobo_dummy(form,
n = 384,
file = NULL)
#> Warning: Expected 2 pieces. Additional pieces discarded in 1 rows [376].
# openxlsx::write.xlsx(datalist, here::here("inst", "dummy_RMS_CAPI_v3.xlsx"))
## CATI
form <- system.file("RMS_CATI_v0.xlsx", package = "IndicatorCalc")
datalist <- fct_kobo_dummy(form,
n = 384,
file = NULL)
# openxlsx::write.xlsx(datalist, here::here("inst", "dummy_RMS_CATI_v0.xlsx"))
form <- system.file("RMS_CATI_v3.xlsx", package = "IndicatorCalc")
datalist <- fct_kobo_dummy(form,
n = 384,
file = NULL)
#> Warning: Expected 2 pieces. Additional pieces discarded in 1 rows [326].
# openxlsx::write.xlsx(datalist, here::here("inst", "dummy_RMS_CATI_v3.xlsx"))Data Wrangling
Each indicator calculation is based on predefined frame, variable name and variable value. Some data wrangling is therefore required before performing the calculations.
The packages comes with tool to support this task. The original data
can be transformed with the function fct_re_map(). The mapper object is
build with the fct_build_map() function, which require 2
files:
IndicatorRequirementFilethi files is created from the orginal template and indicator scripts. It creates a mapping between question variables and indicator variables.mappingfilethis one is created once and is designed to double check that the mapping can actually be performed. To obtain this file, we Apply fuzzy matchingfct_var_mapping()to map within a specified XlsForm the expected variables for indicator calculation. The output is a convenient excel file that will need to be manually revised. The process is very similar than data cleaning with a cleaning log as implemented within {cleaningtools}
The data wrangling is then done with the function
fct_re_map() to obtain the data in the exact format
expected by the indicator calculation functions
Before doing indicator calculation, fct_check_map()
checks that standard frame/variable/modalities are present in the
dataset.
fct_var_mapping
# Test the function
form <- system.file("RMS_CAPI_v2.xlsx", package = "IndicatorCalc")
IndicatorRequirementFile <- system.file("RMS_CAPI_v2_mapper.xlsx", package = "IndicatorCalc")
# Get the map to revise
mapper <- fct_var_mapping(xlsformpath = form,
IndicatorRequirementFile = IndicatorRequirementFile,
mappingfile_out = tempfile())
# here::here("inst", "RMS_CAPI_v2_mapping.xlsx"))fct_build_map
mappingfile <- system.file("RMS_CAPI_v2_mapping.xlsx",
package = "IndicatorCalc")
IndicatorRequirementFile <- system.file("RMS_CAPI_v2_mapper.xlsx",
package = "IndicatorCalc")
mappermain <- fct_build_map(mappingfile = mappingfile,
IndicatorRequirementFile = IndicatorRequirementFile,
thisMeasureLevel = "main")
mapperind <- fct_build_map(mappingfile = mappingfile,
IndicatorRequirementFile = IndicatorRequirementFile,
thisMeasureLevel = "ind")fct_get_all_variable_names
datalist <- kobocruncher::kobo_data( system.file("demo_data.xlsx", #"test.xlsx",
package = "IndicatorCalc"))
varname <- fct_get_all_variable_names(datalist = datalist)
head(varname, 10)
#> # A tibble: 10 × 2
#> df value
#> <chr> <chr>
#> 1 main _index
#> 2 main start
#> 3 main end
#> 4 main start_time_1
#> 5 main intro.intro
#> 6 main intro.interviewdate
#> 7 main intro.Bureau
#> 8 main intro.Country
#> 9 main intro.countryname
#> 10 main intro.geopointfct_re_map
mapper = list(
hierarchy = "main",
variablemap = data.frame(
label = c("Does this household use anything for lighting?",
"What source of electricity is used most of the time in this household?"),
variable = c("LIGHT01",
"LIGHT03"),
mappattern = c("LIGHT01",
"LIGHT03") ),
modalitymap = data.frame(
variable = c( "LIGHT01",
"LIGHT03", "LIGHT03", "LIGHT03"),
label = c( "yes",
"No electricity in household", "Other, specify", "Don\'t know"),
standard = c( "1",
"1", "96", "98"),
map = c("yes",
"Noelec", "Other", "Dontknow")
)
)
## One variable is not correctly
datalist <- list(mainhousehold = data.frame(
group.LIGHT01 = c("yes", "yes", "no", "yes", "yes",
"no", "yes", "yes", "yes"),
group.LIGHT03 = c("Noelec", "Other", "Dontknow", "Noelec", "Other",
"Dontknow", "Nuclear", "Other", "Dontknow"))
)
datalist <- fct_re_map(datalist = datalist, mapper = mapper )
#> Mapped levels for LIGHT01 are now: 1, no
#> Mapped levels for LIGHT03 are now: 1, 96, 98, Nuclear
#fct_check_map(datalist = datalist, mapper = mapper )
## Now testing on a full remap...
## Dummy data created with fct_kobo_dummy
datalist <- kobocruncher::kobo_data( system.file("dummy_RMS_CAPI_v2.xlsx",
package = "IndicatorCalc"))
## Mapping file created from Dummy data
mappingfile <- system.file("RMS_CAPI_v2_mapping.xlsx",
package = "IndicatorCalc")
IndicatorRequirementFile <- system.file("RMS_CAPI_v2_mapper.xlsx",
package = "IndicatorCalc")
## and now we remap both required variables for main and ind
mappermain <- fct_build_map(mappingfile = mappingfile,
IndicatorRequirementFile = IndicatorRequirementFile,
thisMeasureLevel = "main")
datalist <- fct_re_map(datalist = datalist, mapper = mappermain )
#> ℹ HEA01 variable has more than one variable pattern match in the dataset. We will take the first one but good to check...
#> Mapped levels for HEA01 are now: 1, 2, 3, 4, 5, 96, 98
#> ℹ HEA02 variable has more than one variable pattern match in the dataset. We will take the first one but good to check...
#> Mapped levels for HEA02 are now: 1, 2, 3, 96
#> Mapped levels for HEA03 are now: 0, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 2, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 3, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 4, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 5, 50, 51, 52, 53, 54, 55, 56, 57, 58, 59, 6, 60, 61, 62, 63, 64, 65, 66, 67, 68, 69, 7, 70, 71, 72, 73, 74, 75, 76, 77, 78, 79, 8, 80, 81, 82, 83, 84, 85, 86, 87, 88, 89, 9, 90, 91, 92, 93, 94, 95
#> Mapped levels for LIGHT01 are now: 0, 1
#> ℹ LIGHT02 variable has more than one variable pattern match in the dataset. We will take the first one but good to check...
#> Mapped levels for LIGHT02 are now: 1, 10, 11, 12, 13, 2, 3, 4, 5, 6, 7, 8, 9, 96
#> ℹ LIGHT03 variable has more than one variable pattern match in the dataset. We will take the first one but good to check...
#> Mapped levels for LIGHT03 are now: 1, 2, 3, 4, 5, 6, 7, 8, 96, 98
#> ℹ DWA01 variable has more than one variable pattern match in the dataset. We will take the first one but good to check...
#> Mapped levels for DWA01 are now: 1, 10, 11, 12, 13, 14, 15, 16, 2, 3, 4, 5, 6, 7, 8, 9, 96, 98
#> ℹ DWA02 variable has more than one variable pattern match in the dataset. We will take the first one but good to check...
#> Mapped levels for DWA02 are now: 1, 2, 3
#> Mapped levels for DWA03a are now: 1, 2
#> Mapped levels for DWA03b are now: 0, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 2, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 3, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 4, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 5, 50, 51, 52, 53, 54, 55, 56, 57, 58, 59, 6, 60, 61, 62, 63, 64, 65, 66, 67, 68, 69, 7, 70, 71, 72, 73, 74, 75, 76, 77, 78, 79, 8, 80, 81, 82, 83, 84, 85, 86, 87, 88, 89, 9, 90, 91, 92, 93, 94, 95
#> Mapped levels for DWA04 are now: 0, 1
#> ℹ DWE01 variable has more than one variable pattern match in the dataset. We will take the first one but good to check...
#> Mapped levels for DWE01 are now: 1, 2, 3, 4, 5, 6, 7, 8, 9, 96
#> ℹ DWE02 variable has more than one variable pattern match in the dataset. We will take the first one but good to check...
#> Mapped levels for DWE02 are now: 1, 2, 3, 4, 5, 6, 7, 8, 9, 96
#> ℹ DWE03 variable has more than one variable pattern match in the dataset. We will take the first one but good to check...
#> Mapped levels for DWE03 are now: 1, 10, 11, 12, 13, 2, 3, 4, 5, 6, 7, 8, 9, 96
#> ℹ DWE04 variable has more than one variable pattern match in the dataset. We will take the first one but good to check...
#> Mapped levels for DWE04 are now: 1, 10, 11, 12, 13, 14, 15, 2, 3, 4, 5, 6, 7, 8, 9, 96
#> Mapped levels for DWE05 are now: 0, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 2, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 3, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 4, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 5, 50, 51, 52, 53, 54, 55, 56, 57, 58, 59, 6, 60, 61, 62, 63, 64, 65, 66, 67, 68, 69, 7, 70, 71, 72, 73, 74, 75, 76, 77, 78, 79, 8, 80, 81, 82, 83, 84, 85, 86, 87, 88, 89, 9, 90, 91, 92, 93, 94, 95
#> Mapped levels for DWE08 are now: 0, 1
#> Mapped levels for DWE09 are now: 1, 2, 3, 4
#> Mapped levels for HH01 are now: 0, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 2, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 3, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 4, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 5, 50, 51, 52, 53, 54, 55, 56, 57, 58, 59, 6, 60, 61, 62, 63, 64, 65, 66, 67, 68, 69, 7, 70, 71, 72, 73, 74, 75, 76, 77, 78, 79, 8, 80, 81, 82, 83, 84, 85, 86, 87, 88, 89, 9, 90, 91, 92, 93, 94, 95
#> Mapped levels for SAF01 are now: 1, 2, 3, 4, 98, 99
#> Mapped levels for GBV01a are now: 0, 1, 98
#> Mapped levels for GBV01b are now: 0, 1, 98
#> Mapped levels for GBV01c are now: 0, 1, 98
#> Mapped levels for GBV01d are now: 0, 1, 98
#> Mapped levels for VAW01a are now: 0, 1, 99
#> Mapped levels for VAW01b are now: 0, 1, 99
#> Mapped levels for VAW01c are now: 0, 1, 99
#> Mapped levels for VAW01d are now: 0, 1, 99
#> Mapped levels for VAW01e are now: 0, 1, 99
#> Mapped levels for BIR01 are now: 0, 1
#> Mapped levels for BIR02 are now: 0, 1
#> ℹ BIR03 variable has more than one variable pattern match in the dataset. We will take the first one but good to check...
#> The following `from` values were not present in `x`: 2, 3, 4, 5, 6, 96, 98
#> Mapped levels for BIR03 are now: 0, 1
#> ℹ BIR04 variable has more than one variable pattern match in the dataset. We will take the first one but good to check...
#> Mapped levels for BIR04 are now: 1, 2, 3, 96
#> ℹ TOI01 variable has more than one variable pattern match in the dataset. We will take the first one but good to check...
#> Mapped levels for TOI01 are now: 1, 10, 11, 12, 2, 3, 4, 5, 6, 7, 8, 9, 96
#> Mapped levels for TOI02 are now: 1, 2, 98
#> ℹ COOK02 variable has more than one variable pattern match in the dataset. We will take the first one but good to check...
#> Mapped levels for COOK02 are now: 1, 10, 2, 3, 4, 5, 6, 7, 8, 9, 96
#> ℹ COOK03 variable has more than one variable pattern match in the dataset. We will take the first one but good to check...
#> Mapped levels for COOK03 are now: 1, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 2, 20, 21, 3, 4, 5, 6, 7, 8, 9, 96
#> Mapped levels for BANK01 are now: 0, 1
#> Mapped levels for BANK02 are now: 0, 1
#> Mapped levels for BANK03 are now: 0, 1
#> Mapped levels for BANK04 are now: 0, 1
#> Mapped levels for BANK05 are now: 0, 1
#> Mapped levels for INC01 are now: 1, 2, 3, 98
#> Mapped levels for UNEM01 are now: 0, 1
#> Mapped levels for UNEM02 are now: 0, 1
#> Mapped levels for UNEM03 are now: 0, 1
#> Mapped levels for UNEM04 are now: 0, 1
#> Mapped levels for UNEM05 are now: 0, 1
#> Mapped levels for UNEM06 are now: 1, 2, 3
#> Mapped levels for UNEM07 are now: 1, 2, 3
#> Mapped levels for UNEM08 are now: 1, 2, 3, 4
#> Mapped levels for UNEM09 are now: 0, 1
#> Mapped levels for UNEM10 are now: 0, 1
#> ℹ DWE06 variable has more than one variable pattern match in the dataset. We will take the first one but good to check...
#> Mapped levels for DWE06 are now: 1, 2, 3, 4, 5, 6, 7, 8, 9, 96, 98, 99
#> ℹ DWE07 variable has more than one variable pattern match in the dataset. We will take the first one but good to check...
#> Mapped levels for DWE07 are now: 1, 10, 11, 2, 3, 4, 5, 6, 7, 8, 9, 96, 98, 99
#> ℹ DWE10 variable has more than one variable pattern match in the dataset. We will take the first one but good to check...
#> Mapped levels for DWE10 are now: 1, 2, 3, 4, 5, 6, 96
#> Mapped levels for DWE11 are now: 1, 2, 3, 4, 99
#> Mapped levels for SPF01a are now: 0, 1, 98
#> Mapped levels for SPF01b are now: 0, 1, 98
#> Mapped levels for SPF01c are now: 0, 1, 98
#> Mapped levels for SPF01d are now: 0, 1, 98
#> Mapped levels for SPF01e are now: 0, 1, 98
#> Mapped levels for SPF01f are now: 0, 1, 98
#> Mapped levels for SPF01g are now: 0, 1, 98
#> Mapped levels for SPF01h are now: 0, 1, 98
mapperind <- fct_build_map(mappingfile = mappingfile,
IndicatorRequirementFile = IndicatorRequirementFile,
thisMeasureLevel = "ind")
datalist <- fct_re_map(datalist = datalist, mapper = mapperind )
#> Mapped levels for HACC01 are now: 0, 1
#> ℹ HACC02 variable has more than one variable pattern match in the dataset. We will take the first one but good to check...
#> The following `from` values were not present in `x`: 2, 3, 4, 5, 96
#> Mapped levels for HACC02 are now: 0, 1
#> Mapped levels for HACC03 are now: 0, 1
#> ℹ HACC04 variable has more than one variable pattern match in the dataset. We will take the first one but good to check...
#> The following `from` values were not present in `x`: 2, 3, 4, 5, 6, 7, 8, 9, 10, 96
#> Mapped levels for HACC04 are now: 0, 1
#> Mapped levels for EDU01 are now: 0, 1
#> Mapped levels for EDU02 are now: 0, 1
#> Mapped levels for EDU03 are now: 1, 2, 3, 4, 5, 6, 98
#> ℹ EDU04 variable has more than one variable pattern match in the dataset. We will take the first one but good to check...
#> Mapped levels for EDU04 are now: 1, 2, 3, 4, 5, 96, 98
#> ℹ HH07 variable has more than one variable pattern match in the dataset. We will take the first one but good to check...
#> Mapped levels for HH07 are now: 0, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 2, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 3, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 4, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 5, 50, 51, 52, 53, 54, 55, 56, 57, 58, 59, 6, 60, 61, 62, 63, 64, 65, 66, 67, 68, 69, 7, 70, 71, 72, 73, 74, 75, 76, 77, 78, 79, 8, 80, 81, 82, 83, 84, 85, 86, 87, 88, 89, 9, 90, 91, 92, 93, 94, 95
#> Mapped levels for REG03 are now: 0, 1, 98
#> Mapped levels for REG04 are now: 0, 1, 98, 99
#> Mapped levels for REG01a are now: 0, 1, 99
#> Mapped levels for REG01b are now: 0, 1, 99
#> Mapped levels for REG01c are now: 0, 1, 99
#> Mapped levels for REG01d are now: 0, 1, 99
#> Mapped levels for REG01e are now: 0, 1, 99
#> Mapped levels for REG01f are now: 0, 1, 99
#> Mapped levels for REG01g are now: 0, 1, 99
#> Mapped levels for REG02 are now: 0, 1, 99
#> Mapped levels for REG05a are now: 0, 1, 99
#> Mapped levels for REG05b are now: 0, 1, 99
#> Mapped levels for REG05c are now: 0, 1, 99
#> Mapped levels for REG05d are now: 0, 1, 99
#> Mapped levels for REG05e are now: 0, 1, 99
#> Mapped levels for REG05f are now: 0, 1, 99
#> Mapped levels for REG06 are now: 0, 1, 99
#> Mapped levels for COMM01 are now: 0, 1
#> Mapped levels for COMM02 are now: 0, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 2, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 3, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 4, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 5, 50, 51, 52, 53, 54, 55, 56, 57, 58, 59, 6, 60, 61, 62, 63, 64, 65, 66, 67, 68, 69, 7, 70, 71, 72, 73, 74, 75, 76, 77, 78, 79, 8, 80, 81, 82, 83, 84, 85, 86, 87, 88, 89, 9, 90, 91, 92, 93, 94, 95
#> Mapped levels for COMM03 are now: 0, 1, 98
#> Mapped levels for COMM04 are now: 0, 1, 98
#> Mapped levels for MMR03 are now: 0, 1, 98
#> ℹ TOI03 variable has more than one variable pattern match in the dataset. We will take the first one but good to check...
#> Mapped levels for TOI03 are now: 1, 2, 3, 4, 5, 96, 98
#> ℹ TOI04 variable has more than one variable pattern match in the dataset. We will take the first one but good to check...
#> Mapped levels for TOI04 are now: 1, 2, 3
#> Mapped levels for TOI05 are now: 0, 1
#> Mapped levels for COOK01 are now: 0, 1
## Writing this in the installation folder of the packages to run all examples
# openxlsx::write.xlsx( list ( main = as.data.frame(datalist[["main"]]),
# ind = as.data.frame(datalist[["ind"]]) ),
# here::here("inst","dummy_RMS_CAPI_v2_mapped.xlsx"))fct_check_map
## below is the mapper to chck if we have the variables to calculate the
# electricity subindicators within impact 2.2
mapper = list(
hierarchy = "main",
variablemap = data.frame(
label = c(
"Does this household use anything for lighting?",
"What source of electricity is used most of the time in this household?"),
variable = c("LIGHT01",
"LIGHT03") ),
modalitymap = data.frame(
variable = c( "LIGHT01",
"LIGHT03", "LIGHT03", "LIGHT03"),
label = c( "yes",
"No electricity in household", "Other, specify", "Don\'t know"),
standard = c( "1",
"1", "96", "98")
)
)
## Correct format
data <- list(main = data.frame(
LIGHT01 = c("1", "1", "0", "1", "1", "0", "1", "1", "1"),
LIGHT03 = c("1", "96", "98", "1", "96", "98", "0", "96", "98"))
)
check <- fct_check_map(datalist = data, mapper = mapper )
#> ✔ LIGHT01
#> ✔ LIGHT03
check
#> [1] "TRUE"
## One variable is not correctly
data <- list(main = data.frame(
LIGHT01 = c("1", "1", "0", "1", "1", "0", "1", "1", "1"),
LIGH03 = c("1", "96", "98", "1", "96", "98", "0", "96", "98"))
)
check <- fct_check_map(datalist = data, mapper = mapper )
#> ✔ LIGHT01
#> ✖ LIGHT03 not found in the dataset.
check
#> [1] "FALSE"
## The first variable does not include a single 1...
data <- list(main = data.frame(
LIGHT01 = c("0", "0", "0", "0", "0", "0", "0", "0", "0"),
LIGHT03 = c("1", "96", "98", "1", "96", "98", "0", "96", "98"))
)
check <- fct_check_map(datalist = data, mapper = mapper )
#> ℹ LIGHT01 misses responses options among : 1
#> ✔ LIGHT03
check
#> [1] "FALSE"Plot
fct_plot_indic_donut
test <- data.frame(
shelter = c(rbinom(20, 1, 0.5), NA, NA, NA, NA, NA, NA) ) |>
dplyr::mutate( shelter =
labelled::labelled( shelter,
labels = c( "Yes" = 1, "No" = 0),
label = "Access to adequate shelter also testing a long title to see if it wraps well"))
fct_plot_indic_donut(indicator = test$shelter,
subtitle_chart = NULL,
caption_chart = NULL,
ordered_threhold = NULL,
iconunicode = "e54f") 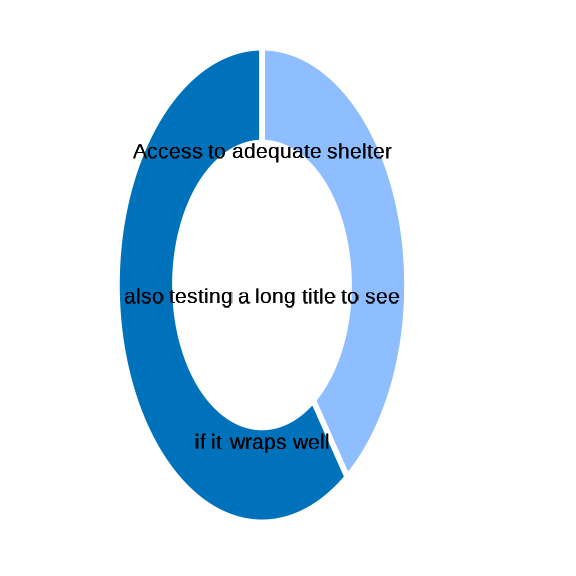
## test no value
test2 <- NULL
fct_plot_indic_donut(indicator = test2,
subtitle_chart = NULL,
caption_chart = NULL,
ordered_threhold = NULL,
iconunicode = "e54f")
#> No value was supplied for plotting...fct_plot_rbm_sdg - SDG Comparison
fct_plot_rbm_sdg( country = "BRA",
rbm = "impact2_2",
years = c(2000, 2022)) +
unhcrthemes::theme_unhcr(font_size = 10)
#> Loading required package: ggplot2
#> Loading required package: dplyr
#>
#> Attaching package: 'dplyr'
#> The following objects are masked from 'package:stats':
#>
#> filter, lag
#> The following objects are masked from 'package:base':
#>
#> intersect, setdiff, setequal, union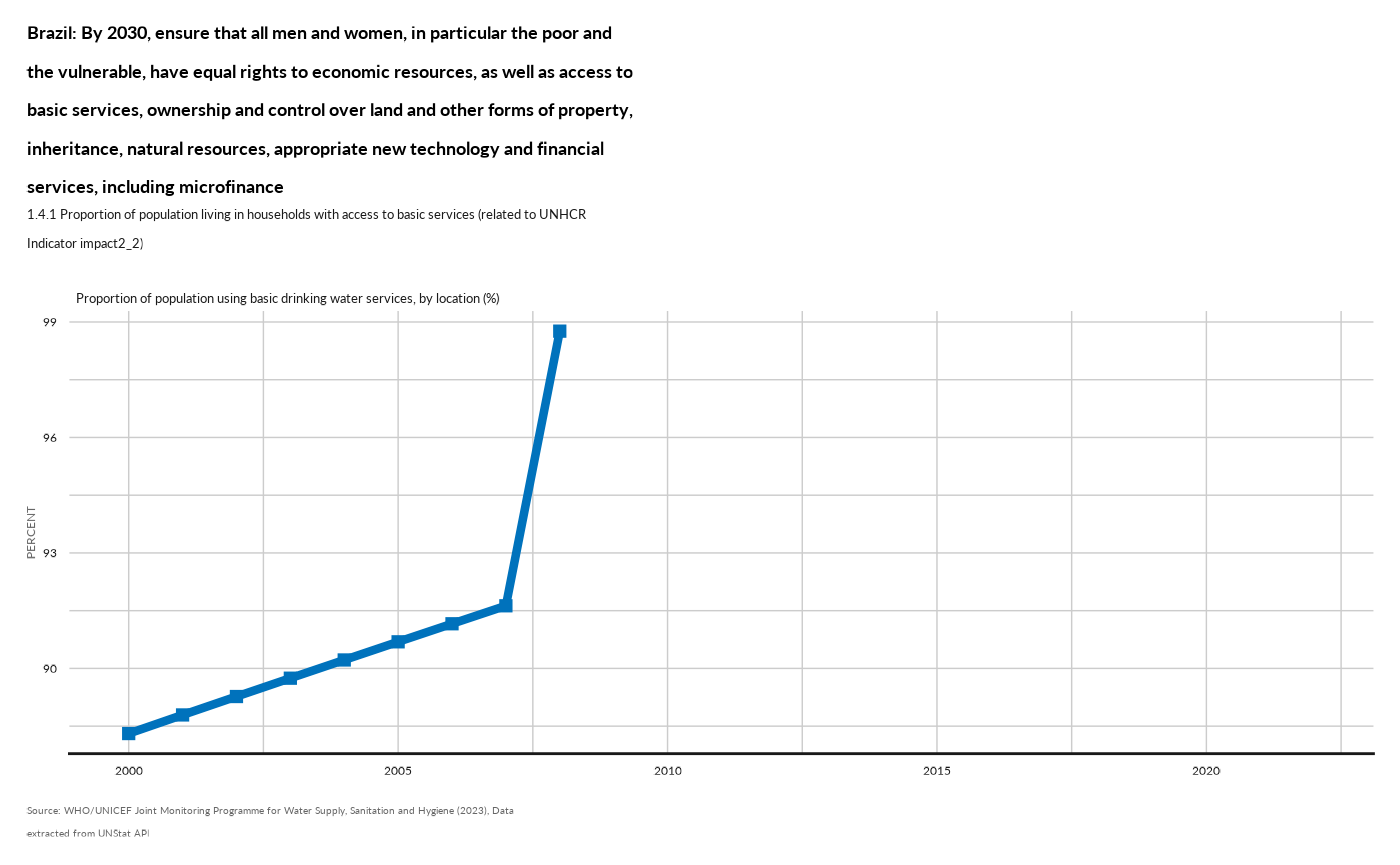
Export Indicator table
fct_compass_table
# compass <- export_compass_fill( country = "ECU",
# operation = "Ecuador ABC",
# year = 2022,
# population_type = c("REF","ASY", "OIP"),
# population_rms = "Refugees and Asylum-seekers",
# rms_indicator = rbind(
# c("main", "impact2_2", "2.2 Proportion of PoCs residing in physically safe and
# secure settlements with access to basic facilities"),
# c("main", "impact2_3", "2.3 Proportion of PoC with access to health services"),
# c("P2.S3", "impact3_2a", "3.2a Proportion of PoC enrolled in primary education" ),
# c("P2.S3", "impact3_2b", "3.2b Proportion of PoC enrolled in secondary education" ),
# c("main", "impact3_3", "3.3 Proportion of PoC feeling safe walking alone in their neighborhood (related SDG 16.1.4)." ),
# c("S2", "outcome1_2", "1.2 Proportion of children under 5 years of age whose births
# have been registered with a civil authority. [SDG 16.9.1 - Tier 1]" ),
# c("S2", "outcome1_3", "1.3 Proportion of PoC with legally recognized identity documents or credentials [GCR 4.2.2]." ),
# c("main", "outcome4_1", "4.1 Proportion of PoC who know where to access available GBV services." ),
# c("main", "outcome4_2", "4.2 Proportion of POCs who do not accept violence against women." ),
# c("main", "outcome8_2", "8.2 Proportion of PoC with primary reliance on clean (cooking) fuels and technology [SDG 7.1.2 Tier 1]" ),
# c("main", "outcome9_1", "9.1 Proportion of PoCs living in habitable and affordable housing." ),
# c("main", "outcome9_2", "9.2 Proportion of PoC that have energy to ensure lighting (close to Sphere)." ),
# c("main","outcome12_1", "12.1 Proportion of PoC using at least basic drinking water services (SDG)." ),
# # c("main" , "outcome12_2", "12.2 Proportion of PoC with access to a safe household toilet (SDG)." ),
# c("main", "outcome13_1", "13.1. Proportion of PoC with an account at a bank or other
# financial institution or with a mobile-money-service provider [SDG 8.10.2 Tier 1]." ),
# c("main", "outcome13_2", "13.2. Proportion of PoC who self-report positive changes in their income compared to previous year." ),
# c("main", "outcome13_3", "13.3 Proportion of PoC (working age) who are unemployed." ),
# c("main", "outcome16_1", "16.1. Proportion of PoC with secure tenure rights and/or
# property rights to housing and/or land [revised SDG indicator 1.4.2]." )#,
# # c("main", "outcome16_2", "16.2. Proportion of PoC covered by social protection floors/systems [SDG 1.3.1]." )
# ),
# ridl = params$ridl,
# publish = params$publish )Utilities
fct_build_requirement
## Write in dev/mapper.R each of the function parameters - as recorded in system.file("IndicMap.xlsx", package = "IndicatorCalc")
xlsformpath <- system.file("RMS_CAPI_v2.xlsx", package = "IndicatorCalc")
RMS_CAPI_v2_mapper <- fct_build_requirement(xlsformpath )
#> /tmp/RtmpPIdgag/filec82f1055d2f8
# openxlsx::write.xlsx(RMS_CAPI_v2_mapper, here::here("inst", "RMS_CAPI_v2_mapper.xlsx"))
xlsformpath <- system.file("RMS_CAPI_v3.xlsx", package = "IndicatorCalc")
RMS_CAPI_v3_mapper <- fct_build_requirement(xlsformpath )
#> Warning: Expected 2 pieces. Additional pieces discarded in 1 rows [376].
#> /tmp/RtmpPIdgag/filec82f49f37502
# openxlsx::write.xlsx(RMS_CAPI_v3_mapper, here::here("inst", "RMS_CAPI_v3_mapper.xlsx"))
## CATI
xlsformpath <- system.file("RMS_CATI_v0.xlsx", package = "IndicatorCalc")
RMS_CATI_v0_mapper <- fct_build_requirement(xlsformpath )
#> /tmp/RtmpPIdgag/filec82f1d9d8d8
# openxlsx::write.xlsx(RMS_CATI_v0_mapper, here::here("inst", "RMS_CATI_v0_mapper.xlsx"))
xlsformpath <- system.file("RMS_CATI_v3.xlsx", package = "IndicatorCalc")
RMS_CATI_v3_mapper <- fct_build_requirement(xlsformpath )
#> Warning: Expected 2 pieces. Additional pieces discarded in 1 rows [326].
#> /tmp/RtmpPIdgag/filec82f7575de8
# openxlsx::write.xlsx(RMS_CATI_v3_mapper, here::here("inst", "RMS_CATI_v3_mapper.xlsx"))